2015년 12월에 네이버 웹마스터도구가 업데이트 되면서 네이버 검색 신디케이션도 함께 업그레이드 할 예정이라는 공지를 보며 한 가지 의문이 있었다.
크롤러 기반의 검색엔진은 표준 SEO를 따르는 것이 일반적이다. 구글 스파이더(spider)가 어떻게 작동하는지 보면 검색엔진 원리를 이해하는데 도움이 됨으로 검색엔진 동작 방식에 대해 간단히 정리해 보면 아래와 같다.
구글 크롤러(스파이더)는 URL을 따라 웹 페이지를 이동한다. 이 같은 URL은 야후 디렉토리나 오픈 디렉토리 또는 ISP 업체에서 제공하는 서버 목록의 자주 방문하는 사이트에서 가져 온다.
크롤러가 방문한 웹 페이지에서 새로운 링크(link)를 발견하면 웹 서버에 데이터 정보를 요청하고 이때 웹 서버는 검색엔진에게 웹 페이지 정보를 보내는데 이것이 바로 메타 태그가 포함된 사이트 정보다.(타이틀, 디스크립션, 본문 텍스트, 태그, 링크 정보 등)
크롤러는 추가로 수집한 URL에서 단어와 문구를 분리하여 저장한다. 저장 과정에서 각 단어와 문구(쿼리)에 가중치(weight)와 연관도(relevance)를 부여 한다. 그리고 최종 결과 값을 인덱스(색인)한다.
검색자가 구글 검색창에 검색어를 입력하면 그때 그때 필요한 것을 끄집어 내는 것이 아니라 검색엔진이 미리 준비해 둔 인덱스(색인)를 검색한다. 이 과정이 없으면 검색 결과를 얻기까지 엄청난 시간이 소요될 것이고 기다림에 지친 검색자는 떠나 버릴 것이다.
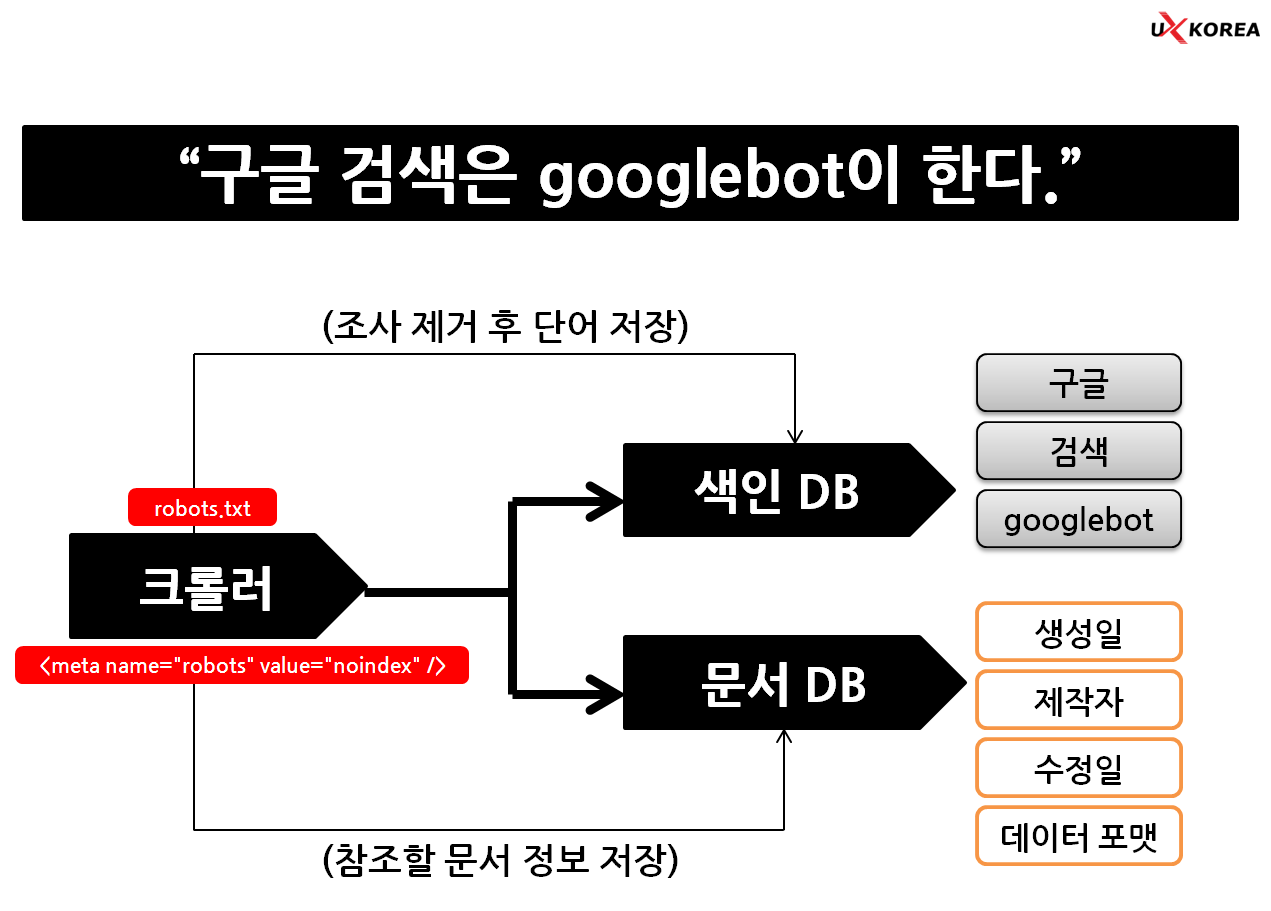
구글 검색엔진 작동 원리
검색엔진의 인덱스는 주기적으로 업데이트 되는데 이 또한 검색엔진마다 다르다. 가중치에 대한 기준도 검색엔진마다 다르며 구체적으로 공개하지 않는다.
예를 들어 웹 페이지에 등장한 키워드 출현 빈도에 가중치를 주는 검색엔진과 문서 상단에 나타난 키워드에 가중치를 주는 검색엔진이 있다. 네이버처럼 검색문구(쿼리)가 접수되면 특정 형태소에 가중치를 주는 경우도 있다.
검색 만족도를 높이기 위해 한 가지만 사용하지 않고 여러 알고리즘을 복합적으로 사용하는 경우가 일반적이다. 참고로 구글은 200여 개 항목으로 년 평균 500회 정도 업데이트하는데 거의 매일 변화가 일어나고 있다고 보면 된다.
이상의 내용이 일반적인 검색엔진 작동 원리다. 네이버는 12월에 있을 업데이트에서 메타 태그와 함께 페이스북의 og 태그를 적용한다고 공개했다. 페이스북이 아무리 대세라곤 하나 검색 환경에 최적화된 표준 메타 정보 외에 페이스북 OG 태그를 추가한 것이 특이한 점이다.
네이버 뉴스 검색은 뉴스 스탠드로 바뀐후 OG 태그가 반영되고 있었다지만 그건 공식적으로 뉴스 스탠드 제휴된 50여 언론사 사이트에 적용한 것이기에 이해는 되지만 일반 웹 검색까지OG 태그를 적용한다는 발표는 다소 의외였는데 이번 컨퍼런스에서 발표된 라이브 검색을 들으며 ‘이거 때문이었구나’ 하는 생각이 들었다.
네이버가 발표한 ‘라이브 검색’ 자체만 두고 보면 새로울 것은 없었다. 이미 몇 년 전부터 네이버가 말해 왔던 것을 이번에 공식적으로 알린 것이다.
이전에도 IP기반의 로컬 검색 결과는 있었다. 데스크탑 성장이 멈추니 only mobile을 공식화 했다지만 이 또한 네이버 내부 소식에 정통한 사람들은 몇 년 전부터 알고 있던 것이다.
글로벌에선 개인정보를 민감하게 생각한다. 예로 구글은 검색자의 쿠키를 사용하지 않아 키워드 값을 제공하지 않아 구글 분석(google analytics)의 유입 키워드 목록에는 ‘not provided’로 표기하고 있다.
MS 빙도 구글과 같다. 그럼에도 네이버는 로그인 했을 때 개인정보를 바탕으로 맞춤 검색 결과를 제공하겠다는 뜻을 내비친 것이다.
개인화 서비스를 강화할 목적으로 추진 중이란 설명을 네이버 임원이 했는데 검색엔진이나 포털에서 개인화 서비스의 실효성은 이미 실패로 끝난 상황인데 굳이 그 점을 강조한 것도 이해되지 않는다. (네이버는 한동안 블로거 이웃들의 글을 묶어 검색결과에 매칭시켜 보여주는 서비스를 베타로 돌렸으나 지금은 사라진 상태다. 그때 기억으론 검색 결과가 그다지 좋지 않았고 시큰둥한 반응에 그 서비스는 사라진 것으로 기억한다.)
네이버는 최근에 포스트, 블로그, 카페에 이어 지식인까지 해시태그를 적용했다. 포스트 출시 때부터 해시태그를 강하게 드라이브 걸었고 블로그 앱에서도 태그 검색을 강조하고 있는 걸로 보아 모바일에서는 사용자 검색을 해시태그 기반으로 가지 않나 예상 된다.
통합검색이 1세대 검색엔진이였고, 다음이 지식인 검색이었다면 이제부터는 섹션 구분 없이 해시태그 기반의 통합 검색이 되지 않나 싶다. 모바일에는 섹션 나누는 것보다 통합해서 검색자가 많이 찾는 것을 영역 구분 없이 순서대로 보여주는 것이 효과적이기 때문이다.
서울에서 ‘해운대’를 검색하는 사람과, 부산에서 ‘해운대’를 검색하는 사람에게 보여 주는 검색결과를 달리 하는 것은 모바일의 위치정보를 검색에 활용하겠다는 것인데 이 경우 물리적인 위치 정보는 정확히 읽어 낼 수 있지만 검색의도를 어떻게 파악할 것인가? 하는 문제가 있다.
구글 허밍버드의 경우에는 검색어마다 검색자 선호도를 체크해서 많이 찾았던 정보를 먼저 보여준다. 과거에는 많은 정보를 보여주는 것 검색엔진의 성능을 보여주는 방식이었다면 지금은 정확한 정보를 빠르게 찾아 주는 것이 최고 기술이 되었다.
7월에 뱅뱅사거리를 검색했던 사람들은 주로 약속 장소인 스타벅스 커피숍 위치를 확인할 목적의 검색이 많았다면 검색 결과 최상위에 스타벅스 찾아가는 길을 보여주고, 9월에 뱅뱅사거리를 검색한 사람들이 자주 클릭한 웹 페이지가 맛집이었다면 검색결과 화면도 검색 선호도에 따라 업데이트 된다.
그럼 네이버는 어떤 방식을 취할까?
라이브 검색에 관한 언론에 제공한 보도자료를 정리해 보면 아래와 같다.
‘라이브 검색’은 이용자들의 피드백을 참조하고 검색 의도를 파악하는 것이 중요해졌다. 같은 키워드를 검색하더라도 연령이나 관심사, 지역 등 다양한 요소에 따라 다른 결과가 보여지는 것이다.
20대 남성이 네이버에 로그인해 ‘원피스’를 검색했을 때는 일본의 인기 애니메이션 ‘원피스’를 노출한다. 하지만 30대 여성이 같은 단어를 검색했을 때는 네이버쇼핑에서 의류 ‘원피스’를 보여주는 것이다.
이는 모바일 네이버 홈화면 설정과도 연계된다. 올해 네이버는 이용자들이 각자 취향에 따라 뉴스, 연예, 스포츠, 쇼핑, 만화/게임 등 모바일 ‘네이버’ 홈페이지에 처음 노출되는 화면을 편집할 수 있도록 홈화면 서비스를 개편했다.
즉 홈화면 메인에 ‘만화/게임’ 섹션을 포함시킨 20대 남성과 ‘쇼핑’ 섹션을 추가한 20대 여성의 검색 결과를 자연스럽게 다르게 노출시켜 원하는 정보를 빠르게 제공하는 것이다.
서울과 부산에서 서로 다른 이용자가 ‘해운대’를 검색할 때 서울 이용자에게는 ‘해운대로 가는 방법’, ‘부산역 KTX 시간’ 등을 안내해주는 반면 부산 이용자에게는 ‘해운대 주변 맛집’을 우선 보여주는 것도 같은 맥락이다.
네이버는 라이브 검색을 위해 ‘BREW’라는 새로운 검색 시스템을 도입했다. ‘BREW’는 ‘Burst, Real-time, Event-Wise Search System’의 약자로 대용량의 생생한 이용자 피드백과 검색의 맥락 등을 실시간으로 처리하는 검색반영 기술이다.
보도 자료에 의하면 ‘생생한 이용자 피드백’, ‘검색 맥락’, ‘실시간 처리’ 3가지를 핵심 키워드로 볼 수 있을 것 같다. 여기에 가장 근접한 것이 모바일 해시태그 아닐까 싶다. 테스트 삼아 ‘유럽여행’으로 올라 온 해시태그를 수집해서 관계망을 만들어 봤다.
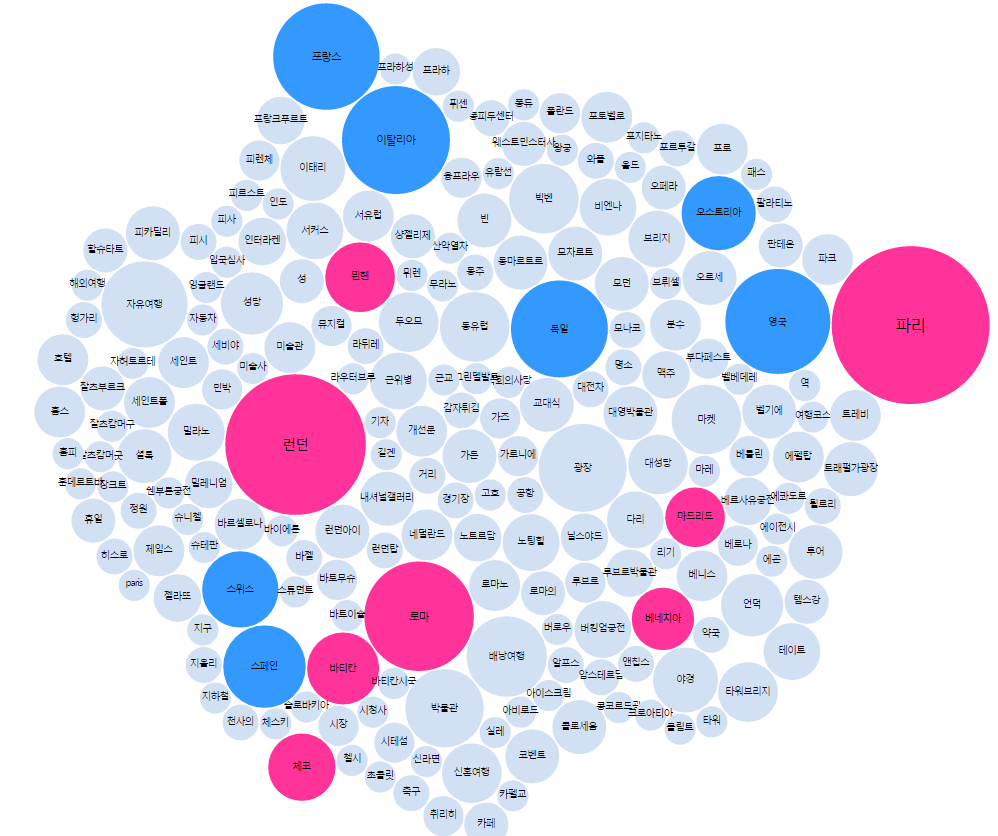
‘유럽여행’ 관련 해시태그 키워드 관계망 분석
‘유럽여행’을 검색하는 사람들이 많이 찾는 도시는 파리, 런던, 로마, 체코 등이며 국가로는 영국, 독일, 프라스, 이탈리아 등. 여행 목적(형태)는 자유여행, 배낭여행, 신혼여행 … 이렇게 검색의도를 찾고, 여행 목적 검색 후 특정 지역(예, 파리) 검색이 발생하면 관련성 높은 지역으로 묶어 제안하는 방식이 가능할 것 같다. 모바일에서는 검색보다 관련 해시태그로 제안해서 보여 주는 방식이 더 편할 것 같다.
네이버 라이브 검색은 크롤러 기반의 검색엔진처럼 100% 알고리즘만으로 처리될 것 같지는 않고 마이닝 결과를 활용해서 인력 기반의 검색엔진고 혼합하지 않을까 싶은 것이 개인 생각이다. 네이버는 통합 검색때부터 편집 방식을 버린 적은 없었다.
<추가 글>



 (주)유엑스코리아 CEO
Facebook : http://fb.com/zinicap.kr
Official Web : http://uxkorea.com
(주)유엑스코리아 CEO
Facebook : http://fb.com/zinicap.kr
Official Web : http://uxkorea.com 

